Anonymous webarchiving
2017-10-05 tags: webarchiving tor pywb webrecorderWebarchiving activities, as any other activity where an HTTP client is involved, leave marks of their steps: the web server you are visiting or crawling will save your IP address in its logs (or even worse it can decide to ban your IP). This is usually not a problem, there are plenty of good reasons for a webserver to keep logs of its visitors.
But sometimes you may need to protect your own identity when you are visiting or saving something from a website, and there a lot of sensitive careers that need this protection: activists, journalist, political dissidents.
TOR has been invented for this, and today offer a good protection to browse anonymously the web.
Can we also archive the web through TOR?
Actually is not difficult: we need the TOR daemon running and then we have to proxy our webarchiving client through it. Every crawler (Heritrix, wget, wpull) can be configured to use a proxy.
Here i want to use pywb, a python implementation of the wayback machine (i wrote about it in the past!), with a new recorder feature that will be soon released (kudos to @IlyaKreymer and @webrecorder).
A quick guide for macos, easy to adapt to GNU/Linux:
Install and run TOR
~ brew install tor
~ echo "TestSocks 1" | tee ~/.torrc
~ tor -f ~/.torrcKeep the daemon running in foreground. Check its output (after the last step) and verify that is logging something like this to be sure that there are no leaks:
Oct 05 12:25:41.000 [notice] Your application (using socks5 to port 42) instructed Tor to take care of the DNS resolution itself if necessary. This is good.Configure torsocks
verify to have version 2.2.0:
~ torsocks --version
Torsocks 2.2.0change the default configuration:
~ TORSOCKS_CONF=/usr/local/Cellar/torsocks/2.2.0/etc/tor/torsocks.conf
~ gsed -i '/AllowInbound/s/^#//g' $TORSOCKS_CONF
~ gsed -i '/AllowOutboundLocalhost/s/^#//g' $TORSOCKS_CONFInstall pywb
install pywb from develop branch
~ pip3 install git+https://github.com/ikreymer/pywb@developcreate an archive
~ mkdir webarchive
~ cd webarchive
~ wb-manager init anonymous-archive
~ echo "recorder:live" | tee config.yamlRun pywb behind TOR
set your shell to use Torsocks by default, every network activity will be proxied trough TOR:
~ . torsocks onrun pywb:
~ wayback --live -a --auto-interval 10record your site:
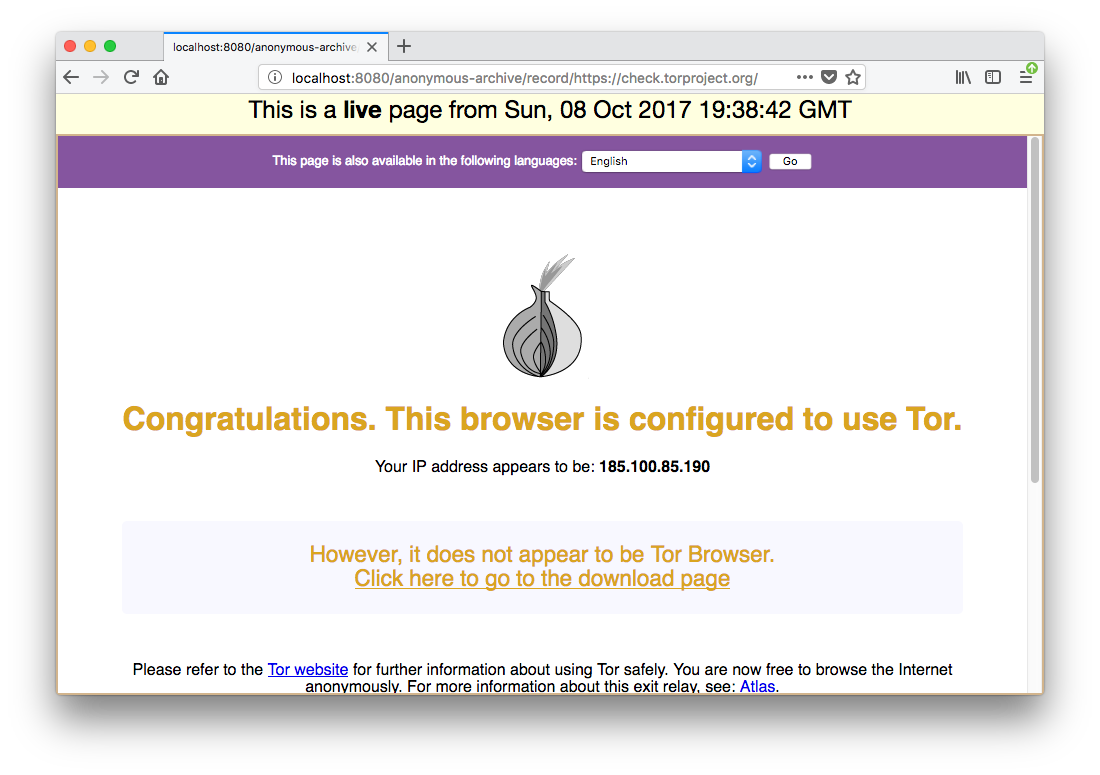
http://localhost:8080/anonymous-archive/record/{URL-TO-RECORD}important: always use a dedicated browser for this, to avoid leaks by extensions or other custom settings. Also make sure to disable DNS Prefetch:
- Firefox:
about:config➜ setnetwork.dns.disablePrefetchtotrue - Chrome: Settings ➜ Advanced ➜ Privacy and security ➜ toggle the "Use a prediction service to load pages more quickly"
Browse the site, everything will be recorded inside
./collections/anonymous-archive
You can replay the recordings still using pywb or also Webrecorder Player
Beware: double check every step and make sure to test it with a known website where you can check the access log to verify that the IP address that is hitting the server is not yours. Or, even better, record https://check.torproject.org and verify if this message is obtained: