Beyond HTTP APIs: the case for database dumps in Cultural Heritage
2024-07-15 tags: digital libraries http api sqlite duckdb parquetIn the realm of cultural heritage, we're not just developing websites; we're creating data platforms. One of the primary missions of cultural institutions is to make data (both metadata and digital content) freely available on the web. This data should come with appropriate usage licenses and in suitable formats to facilitate interoperability and content sharing.
However, there's no universal approach to this task, and it's far from simple. We face several challenges:
- Licensing issues: Licenses are often missing, incomplete, or inadequate (I won't discuss licenses in this post).
- Data format standardization: We continue to struggle with finding universally accepted standards, formats, and protocols.
The current landscape of data distribution methods is varied:
- Data dumps in various formats (CSV, XML, JSON, XLS 💀, TXT)
- HTTP APIs (XML, JSON, RESTful, GraphQL, etc.)
- Data packaging solutions (Bagit, OCFL, Data Package)
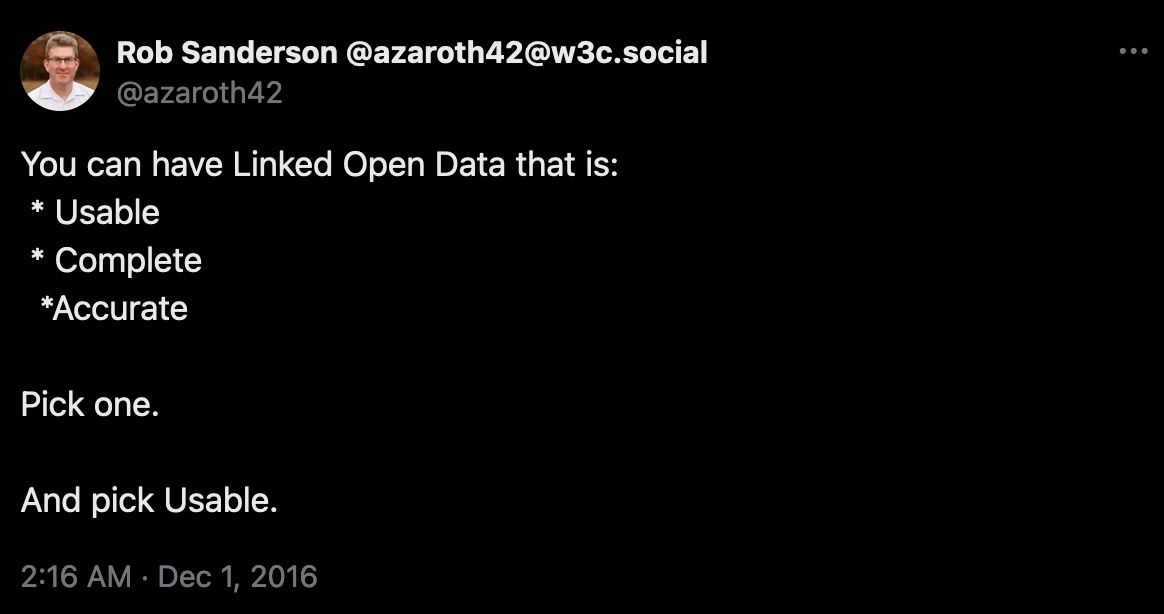
- Linked Open Data (LOD)
While we often advocate for the adoption of Linked Open Data, which theoretically should be the ultimate solution, my experience suggests that the effort required to maintain, understand, and use LOD often renders it impractical and unusable (Wikidata is an exception).
Seeking Simpler Solutions
Can we approach data distribution with simpler solutions? As always, it depends: if there is a need for real-time access to authoritative data, HTTP APIs are necessary (or streaming data solutions like Kafka and similar technologies). But if we can work with a copy of the data, not necessarily updated in real time, then using self-contained and self-describing formats is a viable solution.
I've always thought that the Internet Speculative Fiction Database (ISFDB) publishing of MySQL dumps was a smart move. Here's why:
- An SQL dump includes implicit schema definitions along with the data content.
- While not directly usable, loading it into a working MySQL server is straightforward. You can easily set one up on your laptop.
- Once loaded, you can work with the data offline, eliminating the need for thousands of HTTP calls (and the associated challenges with authentication, caching, etc.)
- SQL is an extremely powerful language and is often one of the first things every programmer should learn.
The Rise of SQLite, DuckDB and Parquet
In recent years, there has been a surge of interest in SQLite, an embedded database that has long been used in many applications. SQLite offers several advantages:
- It's contained in a single file
- It doesn't require a server
- It's fast and efficient
While SQLite isn't suitable for scenarios requiring network access or massive multiple writes, it's perfect for distributing self-contained, ready-to-use data.
It's worth noting the significant contributions of Simon Willison in this area, particularly his suite of tools in the Datasette project. Other notable figures in this field include:
- Alex Garcia
- Ben Johnson for Litestream
- Anton Zhiyanov
An extremely powerful new tool, similar to SQLite, that recently reached its 1.0 milestone is DuckDB. This column-oriented database focuses on OLAP applications, making it less suitable for generic use in web applications. However, DuckDB has a standout feature: it can read and write Parquet files, a highly efficient data storage format.
I was particularly inspired by Ben Schmidt's blog post, Sharing texts better. It introduced me to Parquet, a smart technology that can provide a robust foundation for data distribution, analysis, and manipulation in the cultural heritage sector. DuckDB makes working with Parquet easy, but there are plenty of libraries (and ETL platforms) to wire Parquet data into any application.
Practical Examples
Let's explore some real-world applications of these technologies in the cultural heritage domain:
1. Digipres Practice Index
The Digital Preservation Practice Index is an experiment by Andy Jackson that collects sources of information about digital preservation practices. It's already distributed as a SQLite file and can be browsed using Datasette Lite, requiring only a web browser and no additional software installation.
In this repository, I demonstrate the simple steps needed to convert the SQLite file to Parquet format using DuckDB. The resulting file can be queried directly in the browser using DuckDB Shell (note: it reads Parquet with HTTP Range Requests, so the file is partially downloaded over the network).
2. ABI Anagrafe Biblioteche Italiane
Italian institutions publish a lot of open data, but everything is deeply fragmented: a lot of ontologies, many APIs (official and unofficial), and many dumps with undocumented schemas.
For example, the Register of Italian Libraries provides a zip file containing some CSVs and XML files, and you need to struggle a bit to link pieces together. In this repository https://github.com/atomotic/abi, I created some scripts to transform all those sources into a Parquet file. XMLs are converted to JSON, which is still not the perfect approach, but a single file of 5MB contains all that information. And you can play with it online using the DuckDB shell.
3. BNI Bibliografia Nazionale Italiana
The Italian National Bibliography (BNI) is the official repertory of publications published in Italy and received by the National Central Library of Florence in accordance with legal deposit regulations. The dumps consist of several XML files, each containing a list of records in Unimarc XML format.
In this repository https://github.com/atomotic/bni, I have created some scripts to scrape the content and convert it to Parquet. The XML sources were ~275MB, while the resulting Parquet file is just 70MB.
The Case for Self-Contained Data Formats
When APIs are not strictly necessary, distributing data in self-contained formats can significantly enhance usability and efficiency. The advantages:
- Users can work offline and faster
- Reduced server maintenance: with less reliance on real-time data serving, institutions can allocate fewer resources to maintaining complex API infrastructures.
- Scalability: Self-contained data formats are inherently more scalable, as they don't suffer from traffic spikes that can overwhelm API servers.
In these crazy times of rapid advancement in Large Language Models (LLMs) and AI technologies, it's increasingly likely that your content will be scraped by external entities (setting aside ethical or political considerations for now). By providing data dumps, you can mitigate potential issues for your infrastructure.