Gli oggetti digitali del catalogo SBN
2024-11-01 tags: sbn digital libraries api sql SQLite DuckDBHo recentemente scoperto la disponibilità delle API del catalogo SBN, sebbene non sappia da quanto tempo siano state rilasciate. È un argomento di cui mi sono interessato in passato, più per curiosità personale che per necessità professionale, credendo molto nel valore di dati e metadati aperti nel settore dei beni culturali. Anni fa avevo individuato l'esistenza di alcune API non ufficiali utilizzate dalle applicazioni mobili del catalogo, che ancora oggi funzionano, seppur con funzionalità limitate. Queste API continuano a suscitare interesse in ricercatori o sviluppatori che mi contattano per avere ulteriori dettagli, che purtroppo non sono in grado di fornire.
Quella che segue è una mia analisi di queste nuove API ufficiali del catalogo SBN, e il modo in cui le ho utilizzate per uno specifico caso di studio: ottenere l'elenco dei documenti per i quali è disponibile una risorsa digitale. L'intero catalogo SBN conta 20+ milioni di documenti. Il sottoinsieme che a me interessa, con i documenti digitalizzati, poco meno di un milione (938.000+). Ottenere la lista dei documenti di cui è disponibile l'oggetto digitale mi è sembrato un buon esperimento per esplorare il catalogo in modo casuale e scoprirne qualche contenuto rilevante (serendipità!).
Ho riscontrato alcune particolarità nella modellazione dei dati, e la mancanza di una documentazione dettagliata e completa mi ha fatto procedere a tentativi e intuizioni. Non intendo criticare o sminuire il lavoro svolto dall'ICCU, anzi credo che sia un risultato importante e spero che una maggiore discussione pubblica su questi strumenti e interfacce sui dati possa contribuire a migliorarli e incentivarne l'utilizzo.
Voglio però precisare che negli ultimi tempi ho maturato una visione diversa e meno ortodossa sul modo in cui i dati dei beni culturali dovrebbero essere distribuiti: ne ho scritto qui Beyond HTTP APIs: the case for database dumps in Cultural Heritage, sostenendo che dovremmo preferire degli export completi, autonomi e pronti all'uso rispetto alle API.
Quickstart per usare le API
Le API sono raggiungibili da questo portale https://api.iccu.sbn.it/devportal/apis. L'utilizzo non è pubblico e anonimo, per potere essere usate è necessario registrare un account e successivamente creare delle chiavi OAuth2, che serviranno per generare un token da includere in tutte le chiamate.
Il prodotto software qui usato è WSO2 API manager e da quello che ho potuto capire espone direttamente delle API di Solr (in sola lettura, ovviamente). Esistono diverse API, divise per servizio, presentate graficamente con una sorta di tavola periodica. Non è immediatamente chiaro a cosa di riferiscono e la terminologia usata è per persone che già conoscono l'ecosistema dei servizi di SBN. A me risulta del tutto ignoto cosa siano CA (Cataloghi Storici) oppure IC (ICFE Services), e ho intuito che AB si riferisse all'Anagrafe Biblioteche. Ma quello a cui sono interessato è SB, SBN Integrato.
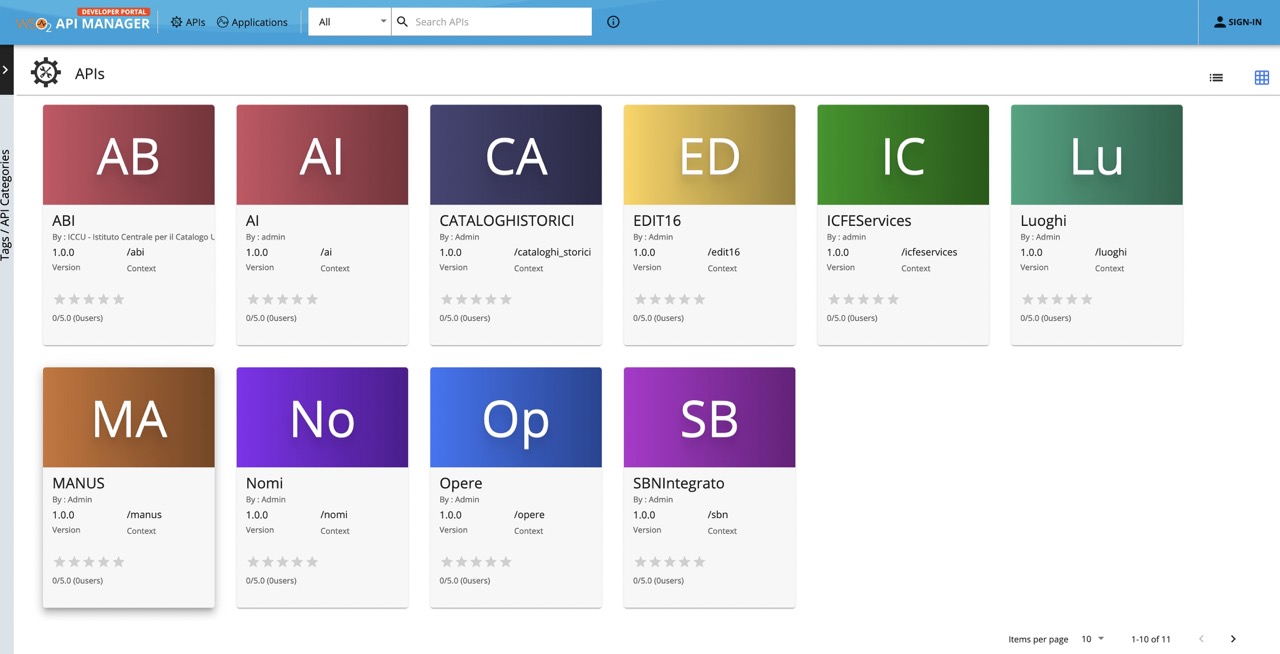
Ognuna della API ha ovviamente delle chiamate e delle risposte di tipo diverso. Sono messi a disposizione degli SDKs già pronti in Java e Javascript. Per la mia attività ho preferito iniziare a scrivere una libreria in linguaggio Go: la trovate qui https://github.com/atomotic/iccu. Non è un SDK completo, è ancora un modulo molto spartano, e col tempo potrei completarlo.
La cattura dei documenti con oggetto digitale
Per esplorare il catalogo ho abbandonato fin da subito l'idea di interpretare in tempo reale le risposte delle API: ho deciso di salvarmi tutti i dati in locale e poi successivamente parsarli. Ho salvato le risposte in un database SQLite, estremamente semplice: un field doc di tipo json in cui salvo il json raw risultante dalla api, e una colonna bid popolata automaticamente dal field unimarc 003
CREATE TABLE sbn (
bid TEXT GENERATED ALWAYS AS (json_extract(doc, '$.unimarc.fields[1].003')) VIRTUAL,
doc json
);
CREATE INDEX bid_idx on sbn(bid);La API chiamata è la seguente: gli argomenti rilevanti sono presenza_digitale=Y e format=full (diversamente avrete un oggetto minimale non completo di tutto l'unimarc).
GET https://api.iccu.sbn.it/sbn/1.0.0/search
format=json
detail=full
page-size=500
presenza_digitale=YQuesto un esempio completo di risposta di un singolo record RAV0302299 (http://id.sbn.it/bid/RAV0302299).
Ho usato una paginazione abbastanza alta, 500 documenti per risposta. Aumentare il numero di documenti restituiti fa diminuire il numero di chiamate HTTP e può velocizzare tantissimo la cattura; ma c'è il problema che spesso alcuni documenti contengono errori di encoding e il JSON restituito non è valido. Quando li incontrate perderete il contenuto di quei documenti nella finestra di paginazione: è capitato anche nella mia analisi, e non ho ulteriormente indagato ne ho voluto implementare un parsing più efficiente: ho perso qualche migliaio di documenti, ed è un margine di errore accettabile.
Ne ho ottenuto un database di 936500 righe, del peso di 4.7G. Non distribuirò pubblicamente questo database (non ho ben chiara la licenza d'uso di questi dati), ma se qualcuno fosse interessato lo condivido.
Come nel caso di attività di scraping, anche in questo caso di utilizzo di API restano valide delle norme di buona condotta: limitare l'aggressività e la velocità delle chiamate, identificarsi sempre nello User Agent delle chiamate HTTP (anche se queste API hanno un token quindi presumo che l'origine e ogni attività sia sempre rintracciabile).
Il codice usato per la cattura è qui disponibile: https://github.com/atomotic/iccu/cmd/sbn-metadata-fetch
L'analisi e l'esplorazione dei metadati
Pensavo ingenuamente che mi sarebbero state sufficienti delle query SQL nel campo JSON del database SQLite per poter esplorare questi dati: purtroppo la mancanza di uno schema e la modellazione di alcuni dati rendono difficoltoso poter fare tutto in SQL, e ho dovuto scrivermi dei metodi all'oggetto Go che implementassero alcune logiche su questi dati.
Non sono interessato a TUTTI i metadati disponibili, ma solo ad un insieme ridotto, la mia necessità è ottenere i link agli oggetti digitalizzati più che i metadati. Dalla trasformazione dei metadati di origine ho voluto ottenere degli oggetti semplificati come il seguente (sono volutamente mancanti dati come gli autori, etc).
{
"bid": "IT\\ICCU\\VIAE\\007373",
"id": "http://id.sbn.it/bid/VIAE007373",
"idmanus": "",
"title": "Risposta apologetica, e critica alle osservazioni, ed alla lettera del molto reverendo padre Cantova della Compagnia di Gesu, stampate in Milano l'anno 1752. Contro a chi ha ultimamente difesa la necessita dell'amor di Dio nel sagramento della penitenza",
"iiif": [
"https://jmms.iccu.sbn.it/jmms/metadata/UW01alpnX18_/b2FpOmJuY2YuZmlyZW56ZS5zYm4uaXQ6MjE6RkkwMDk4Ok1hZ2xpYWJlY2hpOlZJQUUwMDczNzM_/manifest.json"
],
"link": [
"http://books.google.com/books?vid=IBSC:SC000005684",
"http://books.google.com/books?vid=IBSC:SC000008356",
"http://teca.bncf.firenze.sbn.it/ImageViewer/servlet/ImageViewer?idr=BNCF0003334533"
],
"type": "Testo",
"material": [
"Libro antico"
],
"thumbnails": [
"https://jmms.iccu.sbn.it/jmms/resource/ad/first/UW01alpnX18_/b2FpOmJuY2YuZmlyZW56ZS5zYm4uaXQ6MjE6RkkwMDk4Ok1hZ2xpYWJlY2hpOlZJQUUwMDczNzM_"
],
"start_date": 1753,
"end_date": 1753
}
Lo script https://github.com/atomotic/iccu/cmd/sbn-metadata-transform estrae i dati dal db SQLite e genera un file in formato JSON Lines (~500M). Questo export è così pronto per essere caricato in diversi altri strumenti più adatti all'analisi dei dati, come SOLR o DuckDB.
Ho preferito usare DuckDB, e questo è il modo in cui ho caricato i dati:
~ duckdb sbn.duckdb "create table digital as select * from read_json_auto('sbn.jsonl');"~ duckdb sbn.duckdb
D .schema
CREATE TABLE digital(bid VARCHAR, id VARCHAR, idmanus VARCHAR, title VARCHAR, iiif VARCHAR[], link VARCHAR[], "type" VARCHAR, material VARCHAR[], thumbnails VARCHAR[], start_date BIGINT, end_date BIGINT);Ho esportato il database DuckDB in formato parquet e lo si può scaricare da qui https://atomotic.github.io/data/sbn.digital.parquet (93M).
Il file parquet può essere usato direttamente in DuckDB shell nel browser, senza installare nulla. È sufficiente creare una tabella (esempio):
CREATE TABLE digital AS FROM 'https://atomotic.github.io/data/sbn.digital.parquet';Alcune query dimostrative:
Numero di documenti raggruppati per tipologia
D SELECT
type,
COUNT(*) AS count
FROM digital
GROUP BY type order by count desc;
┌───────────────────────────────────┬────────┐
│ type │ count │
│ varchar │ int64 │
├───────────────────────────────────┼────────┤
│ Testo │ 506962 │
│ Registrazione sonora musicale │ 310053 │
│ Risorsa grafica │ 53829 │
│ Musica manoscritta │ 20721 │
│ Testo manoscritto │ 19221 │
│ Musica a stampa │ 11565 │
│ Registrazione sonora non musicale │ 7180 │
│ Risorsa cartografica a stampa │ 4483 │
│ Risorsa elettronica │ 1965 │
│ Risorsa cartografica manoscritta │ 406 │
│ Risorsa da proiettare o video │ 72 │
│ Oggetto tridimensionale │ 29 │
│ Risorsa multimediale │ 14 │
├───────────────────────────────────┴────────┤
│ 13 rows 2 columns │
└────────────────────────────────────────────┘Numero di manifest IIIF
D SELECT COUNT(*) as manifest
FROM (
SELECT DISTINCT unnest(iiif)
FROM digital
);
┌──────────┐
│ manifest │
│ int64 │
├──────────┤
│ 341324 │
└──────────┘Numero di links esterni
D SELECT COUNT(*) as link
FROM (
SELECT DISTINCT unnest(link)
FROM digital
);
┌─────────┐
│ link │
│ int64 │
├─────────┤
│ 1045225 │
└─────────┘Origine dei link esterni
Riguardo ai link esterni ho voluto estrarre l'host del server e poi raggrupparli, in modo da indentificare la provenienza. Ho utilizzato trurl per il parsing della URL, che mi ha rilevato anche diversi errori di parsing, ma li ho tralasciati considerandoli marginali:
~ duckdb --list sbn.duckdb "SELECT DISTINCT TRIM(unnest(link)) AS unique_links FROM digital;" \
| trurl -f - --get "{host}" --accept-space > urls.txtIl file urls.txt contiene la lista degli host, non ordinata. Sarebbero sufficienti sort, uniq e wc per poter fare dei conteggi, ma c'è topfew (del noto Tim Bray!) che è molto più efficiente.
Google Books, l'Istituto Centrale dei Beni Sonori, e la Teca della BNCF sono le sorgenti predominanti.
~ topfew -n 30 urls.txt
363190 books.google.com
312041 opac2.icbsa.it
134072 teca.bncf.firenze.sbn.it
58043 www.internetculturale.it
46714 books.google.it
12614 www.braidense.it
8558 www.bibliotecamusica.it
6290 www.widejef.com
6091 www.bdl.servizirl.it
5020 archive.org
4284 www.14-18.it
4276 corago.unibo.it
3772 www.google.it
3574 sbn.comune.eboli.sa.it
3562 www.cmarchiviodigitale.com
3177 digiteca.bsmc.it
3103 www.polodigitalenapoli.it
2602 www.aggiornamentisociali.it
2330 hdl.handle.net
2304 www.proquest.com
2280 atena.beic.it
1879 www.fondazionecircoloartistico.it
1698 badigit.comune.bologna.it
1546 doi.org
1431 digital.fondazionecarisbo.it
1431 5.175.50.107
1311 www.omeka.unito.it
1274 www.byterfly.eu
1196 www.repubblicaromana-1849.it
1164 turismo.comune.sanginesio.mc.itTra gli host figurano alcune cose bizzarre, molti IP e anche diversi file linkati da Google Drive (e mi sembra una pessima idea linkare in un catalogo degli oggetti da un file storage)
~ grep drive.google urls.txt | wc -l
467Ancora peggio ci sono anche diversi link a Facebook. E al tempo stesso, mi meraviglio, che non ci siano link verso Wikisource o Wikimedia Commons (ma mi riservo di indagare ulteriormente).
Criticità incontrate
I problemi che ho incontrato non sono di natura tecnica sulle API, ma riguardano la modellazione dei metadati:
-
La struttura non è uniforme. C'è un oggetto unimarc che è una rappresentazione in json dell'xml unimarc (non è comodissimo da parsare ma va bene così), mentre invece ci sono una serie di campi accessori al di fuori di quell'oggetto (come ad esempio i manifest IIIF) oppure altri dati che duplicano informazioni già contenute nell'unimarc. Sospetto che siano dati presenti lì per facilitarne l'accesso. Penso che sia comunque normale per una base dati longeva come SBN dovere essere costretti ad aggiungere al bisogno dei campi accessori.
-
Alcuni valori non sono completi: ad esempio i manifest IIIF riportano solo il path, e manca sempre l'host. Con qualche euristica sono riuscito a ricavarlo, ma sarebbe bene che i valori fossero sempre completi. Altre volte invece ho notato che alcuni campi contengono valori multipli divisi con qualche carattere separatore: è il caso dei link esterni alcune volte divisi da
" | ". -
Locazione dell'oggetto digitale. Ho capito che possono essere di due tipi: manifest IIIF, che vengono anche visualizzati con un viewer direttamente nel catalogo web, oppure sono dei collegamenti a pagine esterne (ma possono esserci entrambi manifest e link). I manifest sono riportati con dei field nel livello principale dell'oggetto: esistono dig_cover, dig_manifest, dig_preview e dig_preview_URL, e non sempre mi è chiara la ridondanza. I link esterni invece sono riportati nell'oggetto
unimarcin 899.u o altri. -
Alcuni vocabolari fanno uso di lettere singole (ad esempio nel campo tipologie e materiale). Questi vocabolari sono scarsamente documentati, in questi casi sarebbe bene usare una URI (risolvibile!) che porti ad una pagina di documentazione. Esempio:
Codice a un carattere del tipo documento: a=Testo b=Testo manoscritto c=Musica a stampa d=Musica manoscritta e=Risorsa cartografica a stampa f=Risorsa cartografica manoscritta g=Risorsa da proiettare o video i=Registrazione sonora non musicale j=Registrazione sonora musicale k=Risorsa grafica l=Risorsa elettronica r=Oggetto tridimensionale m=Risorsa multimediale --- codice ad un carattere del tipo materiale: v=Audiovisivi c=Cartografia g=Grafica A=Libro antico N=Libro moderno M=Musica -
Manca uno schema: questo è il maggiore dei problemi. Ho dovuto procedere a tentativi ed euristiche per potere parsare quelle risposte, e sono certo di non avere individuato tutte le possibili casistiche o possibilità di errori. I metadati hanno bisogno obbligatoriamente di schemi, con i quali poter effettuare validazioni e costraint. Di possibili tecnologie ne esistono diverse, di complessità variabile: JSONSchema, Avro, Protobuf. Penso sia sufficiente un buon JSONSchema per iniziare. Esistono anche alcune cose nuove come PKL o CUE, finora mai impiegate in un ambito di serializzazione di metadati, che secondo me sono interessanti e il mondo delle digital libraries potrebbe iniziare a valutarle.
Conclusioni
Al netto dei problemi di modellazione dei dati mi sembra che l'infrastruttura tecnologica di questo prodotto di API sia altamente funzionante. Mi piacerebbe sapere se esistono delle statistiche di utilizzo o reali di esempi di integrazione su cataloghi o portali esterni. Penso poi che il mondo Wikidata, dove già esistono diverse integrazioni con il catalogo SBN, possa trarre beneficio da queste API e rendere più veloci e automatici diversi processi già esistenti.